Google DeepMind Unveils InfAlign Framework for Language Models
Google DeepMind Unveils InfAlign Framework for Language Models
Google DeepMind 已推出 InfAlign,这是一个新的机器学习框架,旨在增强生成语言模型在推理阶段的对齐能力。该创新框架解决了语言模型在从训练到实际应用转变时面临的重大挑战,特别是在推理过程中的性能优化。
Challenges in Generative Language Models
生成语言模型在训练后通常会遇到实现最佳性能的障碍。一个关键问题在于 推理阶段,模型必须产生可靠的输出。传统方法,如 从人类反馈中进行强化学习 (RLHF),主要集中在提高整体成功率。然而,它们往往忽视重要的解码策略,包括 Best-of-N 采样 和控制解码技术。训练目标与实际部署之间的这种脱节可能导致效率低下,负面影响生成输出的质量。
Introducing InfAlign
为了解决这些挑战,Google DeepMind 与 Google Research 合作开发了 InfAlign。该框架将推理策略整合到对齐过程,旨在弥合训练与应用之间的差距。InfAlign 通过校准的强化学习方法,根据特定的推理策略修改奖励函数。这对 Best-of-N 采样 等技术特别有益,后者生成多个响应以选择最佳响应,以及通常用于安全评估的 Worst-of-N 采样。通过这样做,InfAlign 确保对齐模型在受控环境和现实场景中有效执行。
The CTRL Algorithm
InfAlign 的核心是 校准和转换的强化学习 (CTRL) 算法。该算法分为三个关键步骤:
- 校准奖励分数
- 根据所选推理策略转换这些分数
- 解决 KL 正则化优化问题 通过根据特定场景量身定制奖励转换,InfAlign 成功将训练目标与推理需求对齐。该方法不仅提高了推理过程中的成功率,还确保了计算效率。此外,InfAlign 提高了语言模型的稳健性,使其能够处理各种解码策略,并始终交付高质量的输出。
Experimental Validation
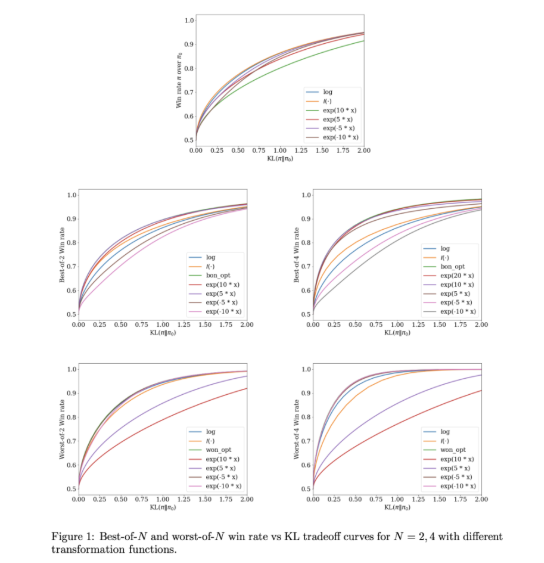
InfAlign 的有效性已通过利用 Anthropic 的数据集进行实验验证,重点关注有用性和无害性。结果表明,InfAlign 在 Best-of-N 采样 中将推理成功率显著提高了 8%-12%,在 Worst-of-N 安全评估中提高了 4%-9%。这些增强归因于校准的奖励转换,有效解决了奖励模型中的误校准问题,确保在多样化的推理场景中表现一致。
Conclusion
InfAlign 标志着生成语言模型对齐的重大进展。通过整合推理感知策略,该框架解决了训练与部署阶段之间的关键差异。其坚实的理论基础和实证结果突显了它全面提升 AI 系统对齐潜力。
For further information, visit InfAlign on Arxiv.
Key Points
- InfAlign 是 Google DeepMind 开发的新框架,旨在增强语言模型在推理阶段的性能。
- 该框架通过校准的强化学习方法调整推理策略的奖励函数,将训练目标与推理需求对齐。
- 实验结果表明,InfAlign 在多个任务中显著提高了模型的推理成功率,展示了良好的适应性和可靠性。