Google DeepMind新型AI训练技术轻松应对硬件故障
Google DeepMind的容错AI训练突破
在人工智能开发这个高风险领域,硬件故障可能导致耗资数百万美元的培训项目陷入停滞。Google DeepMind的最新创新旨在通过一种名为Decoupled DiLoCo的巧妙分布式训练架构改变这一现状。
传统方法的问题
当前的AI训练方法要求所有计算单元完美同步工作——就像一支管弦乐队,每位乐手都必须同时演奏每个音符。当一件乐器走调(或在这种情况下,服务器崩溃)时,整个演出就会停止。
"我们见过太多有前景的项目因为单点故障而脱轨,"一位熟悉该项目的DeepMind研究员解释道,"一个5美元的冷却风扇故障不应该毁掉1000万美元训练项目中数周的进展."
DiLoCo如何改变游戏规则
新系统将计算资源组织成独立的"学习单元",这些单元像自包含的工作坊一样运作。每个单元可以完成多个训练周期,然后与中央协调器共享精简后的更新。这种异步方法意味着:
- 无需等待:单元不会在其他单元追赶时闲置
- 故障恢复能力:一个单元的崩溃不会停止其他单元
- 带宽效率:只有必要数据在单元间传输
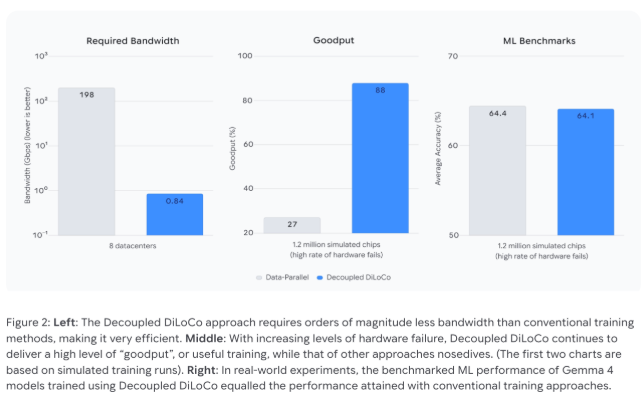
测试结果显示了显著改进。传统方法在硬件故障期间效率降至27%,而DiLoCo保持了88%的利用率。带宽减少更为惊人——从需要专门的198 Gbps连接降至仅0.84 Gbps,使得通过标准互联网链接进行全球协作成为可能。
内置恢复功能
该系统不仅能容忍故障——还能主动绕过它们。在所有学习单元被故意崩溃的压力测试中,DiLoCo在组件重新上线后自动恢复训练而不丢失进度。
也许最令人印象深刻的是,该架构支持在同一训练运行中混合使用不同世代的硬件。旧的TPU芯片可以与新型号一起贡献,可能延长现有基础设施的使用寿命,同时在升级期间缓解过渡期问题。
这对AI开发意味着什么
影响超出了技术弹性范畴:
- 成本节约:减少对超可靠(且昂贵)硬件配置的需求
- 可访问性:小型组织可以参与分布式培训项目
- 可持续性:更好的利用率延长硬件寿命,减少电子垃圾
- 全球协作:带宽减少使跨境合作成为可能
正如一位工程师所说:"我们不仅使AI培训更加稳健——我们还使其更加民主."
关键点:
- 🛡️ 容错设计确保在硬件故障期间持续训练
- 🌍 带宽需求从198 Gbps大幅降至不足1 Gbps
- ♻️ 硬件灵活性允许新旧设备无缝混合使用
- 📈 保持88%效率在故障期间(传统方法仅为27%)


