谷歌AI发布TxGemma:药物研发领域的重大突破
药物研发是一个众所周知的复杂且昂贵的过程,常常伴随着高失败率和漫长的周期。传统方法严重依赖实验验证,消耗大量资源。然而,机器学习和预测建模如今提供了有前景的解决方案来简化这一过程。
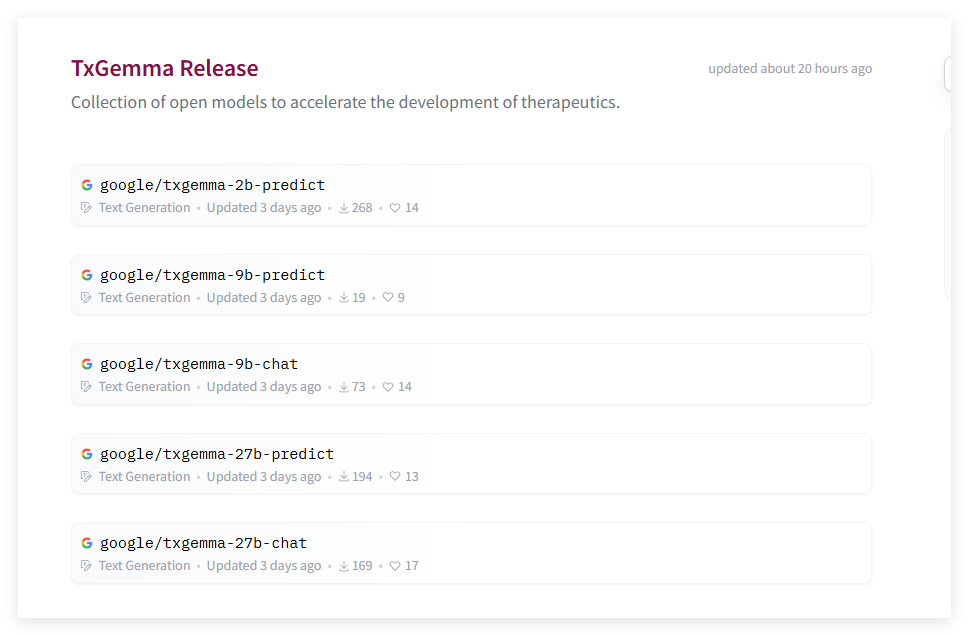
为了应对现有计算模型的局限性,谷歌AI推出了TxGemma,这是一个专为药物研发中治疗任务设计的开创性系列大型语言模型(LLMs)。TxGemma的独特之处在于其整合了多样化数据集,涵盖小分子、蛋白质、核酸、疾病和细胞系。这种全面的方法使模型能够支持治疗管线的多个阶段。
TxGemma系列包括具有2亿(2B)、9亿(9B)和27亿(27B)参数的模型,均基于Gemma-2架构构建,并通过大量治疗数据进行了微调。此外,谷歌还推出了TxGemma-Chat,这是一个交互式对话模型,允许科学家进行详细讨论并获得机制解释,从而增强透明度和可用性。
技术进步
TxGemma利用了包含6600万数据点的强健数据集——治疗数据共享库(TDC)。其预测变体TxGemma-Predict在治疗建模中表现出色,匹配或超越了当前通用和专业模型的性能。值得注意的是,TxGemma在数据稀缺领域表现优异,仅需显著更少的训练样本即可实现高精度。
实际应用
TxGemma的一个突出特点是其能够预测临床试验中的不良事件——这是药物安全评估的关键方面。拥有27B参数的模型在仅需比传统方法少得多的训练样本的情况下,提供了强大的预测性能。这种高效性还辅以其快速的推理速度,使其非常适合虚拟筛选等实时应用。
更广泛的影响
通过公开发布TxGemma,谷歌AI旨在促进跨专有数据集的进一步验证和适应。此举可能加速计算治疗研究的进展,促进可重复性和更广泛的适用性。
该模型可在Hugging Face上获取。
关键点
- TxGemma是一个旨在通过整合数据集优化药物研发任务的LLM系列。
- 这些模型的参数范围从200M到2.7B不等,并包括一个增强透明度的交互式变体。
- TxGemma-Predict在预测不良事件方面优于现有模型且所需训练样本更少。
- 其快速推理速度支持虚拟筛选等实时应用。
- 谷歌的公开发布鼓励了治疗研究中更广泛的采用和验证。