DeepSeek V4 发布双版本:开发者须知要点
DeepSeek V4 采用双轨策略登场
AI领域迎来新变局。中国人工智能领军企业 DeepSeek 推出的 V4 模型暗藏巧思:专为不同工作负载设计的两个版本。这不仅是常规升级——更是可能改变企业AI部署方式的战略举措。
Flash vs Pro:如何选择你的AI主力
新版产品线以两大明确选项取代旧型号:
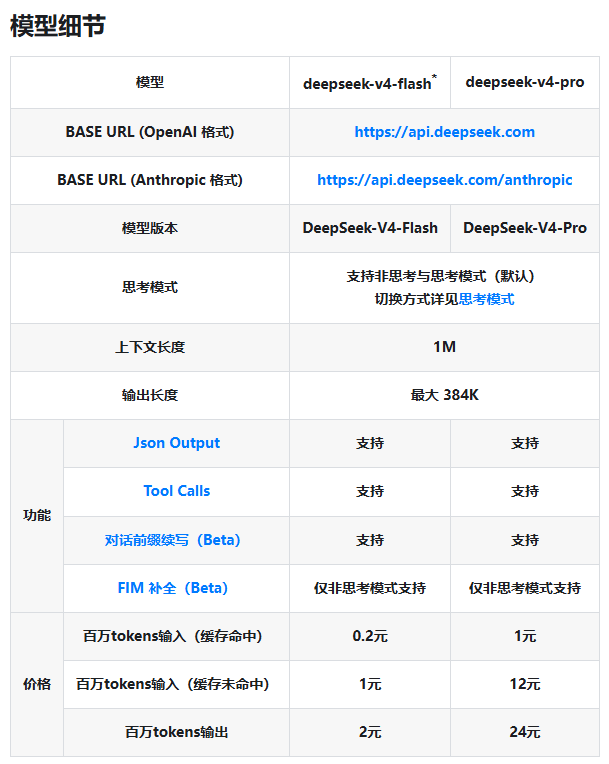
- DeepSeek-V4-Flash:专注速度与经济性,高效处理日常对话和基础文本任务
- DeepSeek-V4-Pro:应对需要重度脑力的场景——复杂分析、深度推理或高强度计算
两版本均支持JSON输出、工具调用等高级功能,并配备128K上下文窗口,为开发者提供充裕的复杂应用空间。
激励高效编程的定价策略
价格体系彰显DeepSeek的资源管理智慧。缓存请求最高可享80%折扣,激励开发者构建更高效的应用程序。每百万token费用如下:
| 模型 | 输入(缓存命中) | 输入(缓存未命中) | 输出 |
|---|
分级定价对初创企业和大型公司同样具有变革意义:Flash版降低顶级AI门槛,Pro版则以合理价格提供强劲性能。
本次发布的深层意义
除技术参数外,此次升级标志着三大趋势:
- 专业化取胜:通用型AI模型时代或将终结,定制化方案正成为主流
- 成本透明化:清晰的计价方式助力企业精准预估成本——相比云服务模糊账单是显著进步
- 性能可选性:开发者能根据预算和需求明确匹配机型
公司同时宣布将逐步停用旧型号命名(如deepseek-chat、deepseek-reasoner),建议开发者立即切换至V4新命名体系。
核心要点速览
- 双模并行:Flash重效率,Pro重性能
- 智能缓存最高节省80%成本
- 128K上下文窗口支持复杂应用场景
- 旧型号即将退役(详见API迁移指南)