DeepSeek V4发布:推出Flash与Pro双版本
DeepSeek V4:Flash与Pro双版本开启AI新时代
AI行业领军者DeepSeek正式推出旗舰模型DeepSeek V4。本次发布不仅是常规更新,更是通过两个专业版本(Flash与Pro)满足多样化需求的战略举措。
量身定制的解决方案
新版产品线取代了原有的deepseek-chat和deepseek-reasoner模型,包括:
- DeepSeek-V4-Flash:快速响应和日常任务的理想选择,主打速度和性价比
- DeepSeek-V4-Pro:应对复杂问题时的强力智囊团
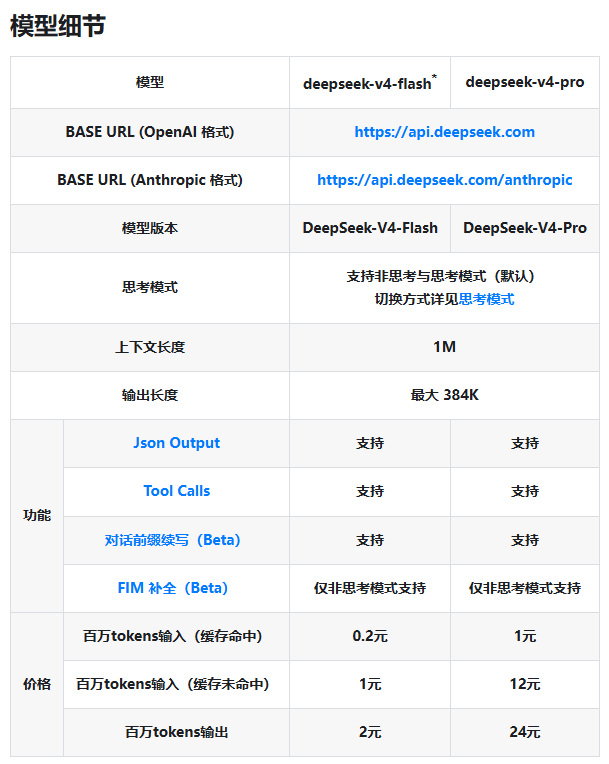
两个版本均支持高达1M的上下文窗口,可处理最长384K token的输出,并配备思维模式(多数场景下)、JSON输出功能和工具调用能力。
透明定价鼓励智能使用
全新定价结构简明直观(单位:百万元token):
| 模型 | 输入(缓存命中) | 输入(缓存未命中) | 输出 |
|---|
缓存命中与未命中的显著价差鼓励开发者优化缓存策略——这是保持性能同时控制成本的明智之举。
本次发布的重要意义
Flash版在缓存未命中场景下仅需¥1/百万元token的定价,使得顶级AI技术触手可及。对于需要更强性能的企业,Pro版以极具竞争力的价格为构建复杂知识库或自动化代理提供强力支持。
公司还简化了迁移流程,允许直接调用新模型名称(deepseek-v4-flash和deepseek-v4-pro),尽管旧命名约定最终将被淘汰。
开发者可通过DeepSeek API官方文档获取完整技术细节。
核心要点:
- 双专业模型:Flash应对日常需求,Pro处理复杂任务
- 高性价比:起价仅¥0.2/百万元token(缓存命中)
- 智能缓存激励:优化实现可获显著成本节省
- 平滑过渡:已支持直接调用新模型名称