DeepSeek R1增强版效率提升200%
DeepSeek R1增强版实现重大效率突破
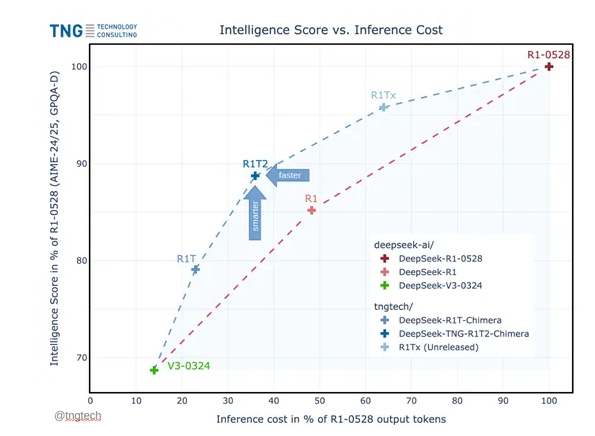
德国技术咨询公司TNG发布了DeepSeek-TNG-R1T2-Chimera,这是DeepSeek模型的增强版本,标志着深度学习性能的显著飞跃。新版本通过创新的自适应专家(AoE)架构展示了200%更高的推理效率,同时降低了运营成本。
混合模型架构
Chimera版本结合了三个DeepSeek模型(R1-0528、R1和V3-0324),采用了一种新颖的AoE架构,改进了传统的专家混合(MoE)方法。这种优化允许更高效的参数使用,在保持令牌输出的同时提升性能。
包括MTBench和AIME-2024在内的基准测试显示,Chimera版本在推理能力和成本效益方面均优于标准R1模型。
MoE架构优势
AoE架构基于MoE原则构建,其中Transformer的前馈层被划分为专门的“专家”。每个输入令牌仅路由到这些专家的一个子集,显著提高了模型效率。例如,Mistral的Mixtral-8x7B模型通过激活远少于大型模型的参数匹配了其性能,展示了这一原则。
AoE方法进一步推进了这一理念,使研究人员能够:
- 从现有MoE框架创建专门的子模型
- 插值并选择性合并父模型权重
- 动态调整性能特征
技术实现
研究人员通过精细的权重张量操作开发了新模型:
- 通过直接文件解析准备父模型权重张量
- 定义权重系数以实现平滑特征插值
- 实施阈值控制和差异过滤以降低复杂性
- 优化路由专家张量以增强子模型推理能力
团队使用PyTorch实现了合并过程,保存优化后的权重以创建最终的高效子模型。

增强版DeepSeek模型现已在Hugging Face开源提供。
关键点:
- 与先前版本相比推理效率提升200%
- 通过AoE架构实现显著成本降低
- 在MTBench和AIME-2024基准测试中超越标准模型
- 基于MoE原则并采用增强的权重合并技术
- 开源可用性促进更广泛的采用和研究



