Claude Opus 4.6在AI基准测试对决中夺冠
Claude在最新AI基准测试中超越GPT
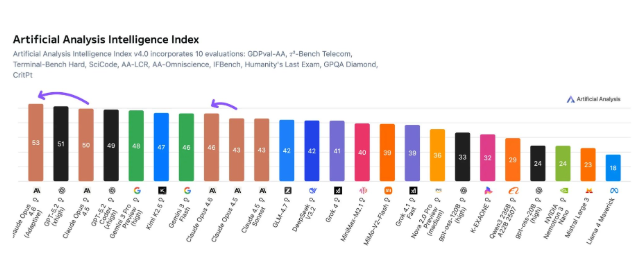
人工智能领域再次洗牌,Anthropic的Claude Opus 4.6在权威的Artificial Analysis Intelligence Index中登顶。这项全面评估通过十项严格测试对AI模型进行检验,从编程挑战到物理问题求解无所不包。
更高成本下的效率胜利
Opus 4.6的表现为何尤其令人印象深刻?该模型在取得基准测试最佳成绩的同时,还展现了卓越的效率。在测试过程中,它处理了约5800万个输出token——相比GPT-5.2的1.3亿token消耗量是显著提升。这一效率优势是在Opus 4.6略高的2486美元运营成本(对比GPT-5.2的2304美元)下实现的。
"这些数字讲述了一个有趣的故事,"AI分析师Mark Chen指出,"虽然两款模型都代表了尖端技术,但Claude似乎在计算资源上获得了更高的性价比。"
Claude的优势领域
基准测试结果揭示了Opus 4.6的突出强项:
- 代理任务执行:在复杂的多步骤操作中胜过所有竞争对手
- 终端编程:展现出更优秀的编码能力
- 物理研究:在科学领域表现出高级推理技能
目前Opus 4.6已在Claude.ai及Google Vertex、AWS Bedrock等主要云平台上线,正在各类应用中证明其价值。
OpenAI即将发起的挑战
然而Anthropic的庆祝可能不会持续太久。行业观察者正密切关注OpenAI的Codex 5.3,该专用编程工具已进入初步测试阶段。早期迹象表明当完整基准结果出炉时,它可能会为OpenAI夺回编码领域的桂冠。
"这场AI竞赛就像观看奥运短跑选手不断打破彼此纪录,"科技记者Sarah Lim评论道,"当一款模型领先时,总会有另一款出现来突破界限。"
关键要点:
- Claude Opus 4.6领跑最新AI智能基准测试
- 处理5800万token vs GPT-5.2的1.3亿——展现更高效率
- 2486美元运营成本略高于GPT-5.2(2304美元)
- 擅长代理任务、终端编程和物理研究领域
- OpenAI的Codex 5.3有望在编码专项基准中发起挑战

