Claude 4.7收敛自夸倾向,聚焦精准表现
Anthropic为Claude 4.7选择差异化路线
当竞争对手追逐更高智力分数时,Anthropic为其最新Claude版本做出了不寻常的决策。4.7版本发布时附带了一个意外声明:"这不是我们最强大的模型"。该公司没有继续突破原始能力边界,而是专注于打造一个更少出错、懂得说"我不知道"的AI。
数据表现依然亮眼
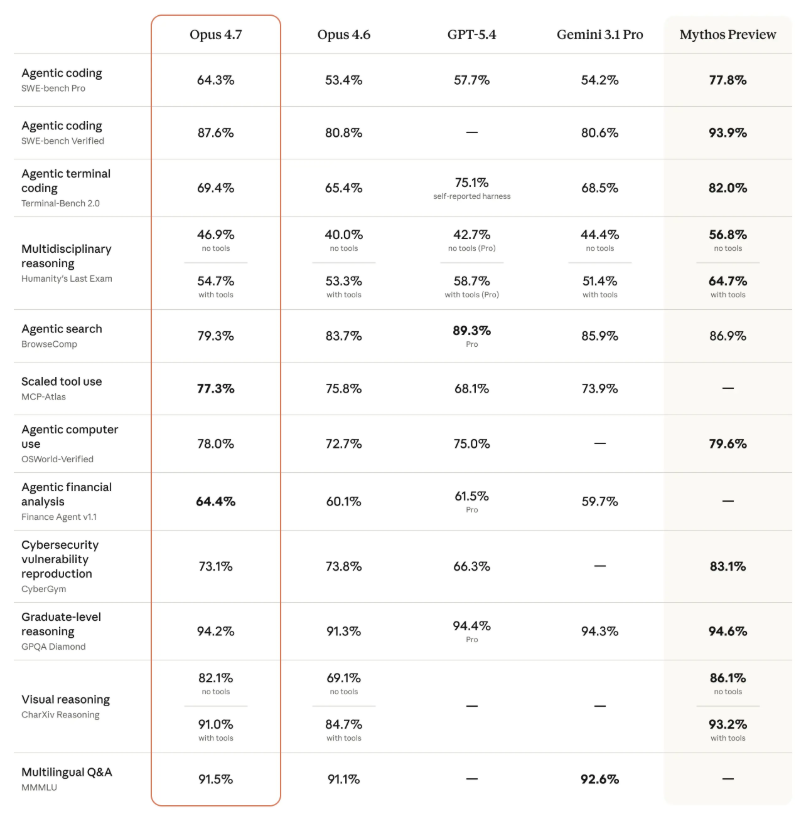
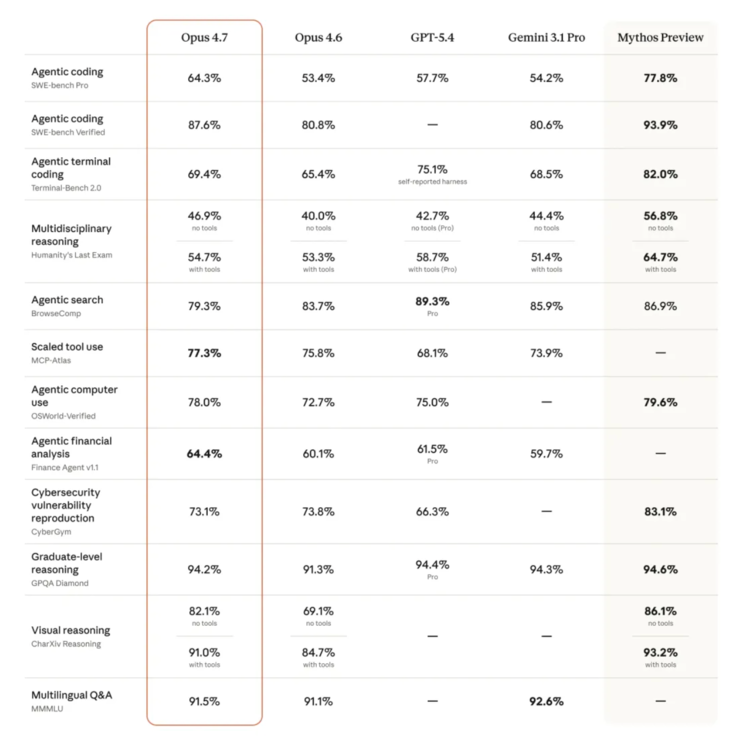
别把可靠性误认为弱点。Claude 4.7在关键基准测试中展现出显著提升:
- SWE-bench Pro(编程领域): 从53.4%跃升至64.3%,超越GPT-5.4(57.7%)和Gemini 3.1 Pro(54.2%)
- CharXiv(视觉推理): 凭借更精准的图像识别,从69.1%提升至82.1%
- 法律AI任务: 在Harvey's BigLaw基准测试中达成90.9%准确率
唯一显著下降的是搜索评估(83.7%至79.3%),正是因为4.7版本在信息缺失时拒绝猜测——这个权衡多数用户都愿意接受。
改变的行为模式
早期使用者注意到了数据之外的变化。"它在技术讨论中会质疑我,"一位Replit高管表示,"就像帮助我做出更好决策的同事。"数据平台Hex观察到该模型现在会承认数据缺口,而非编造看似合理的数字。当工具失效时,4.7版本找到替代方案的几率是前代的三倍。
Vercel工程师发现了一个有趣的新行为:AI现在会在编写系统级代码前进行数学证明,这对语言模型而言展现了罕见的严谨性。
可靠性的代价
这种可靠性需要成本。4.7版本生成相同文本会多产生1-1.35倍的token,在复杂问题上思考时间更长。Anthropic引入了新控制功能来管理这些需求,包括"超高强度"思考模式和面向开发者的预算追踪工具。
与此同时,传闻中的"Mythos"模型仍以"Project Glasswing"的名称进行有限测试,因安全性评估未完成而被认为暂不适合公开发布。
关键要点
- Claude 4.7优先考虑可靠性而非最大化智力
- 尽管采取更保守策略,基准测试仍有显著提升
- 行为改变包括承认不确定性和寻找替代方案
- token使用量增加35%以实现更彻底的处理
- 企业专属"Mythos"模型仍在测试中
这次发布标志着AI发展的有趣转变——有时认清局限比成为房间里最聪明的存在更有价值。