中国MOSS-Speech在AI对话领域取得突破性进展
自然AI对话的重大飞跃
复旦大学的MOSS团队凭借其开创性的MOSS-Speech系统在人工智能领域掀起波澜。与传统语音助手需要将语音转换为文本再转回语音不同,这个新模型完全通过声音处理对话——就像人类一样。
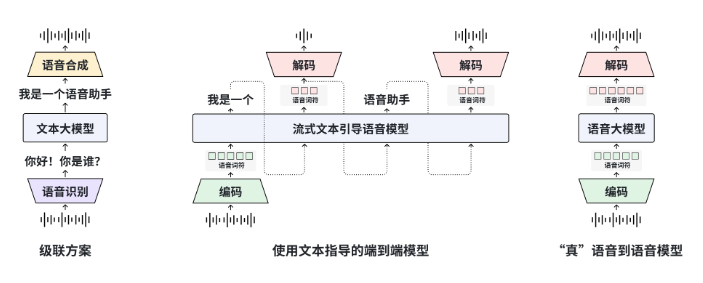
工作原理与众不同
其奥秘在于巧妙的"分层"架构设计。研究人员没有从头开始重建所有内容,而是保留了原始MOSS模型经过验证的文本处理能力不变,然后增加了三个专门层:
- 语音理解层:解读声音模式
- 语义对齐层:连接含义与声音
- 神经声码器:生成自然流畅的响应
这种优雅的方案绕过了Siri、Alexa等数字助手使用的笨拙三步流程(语音转文本→语言处理→文本转语音)。
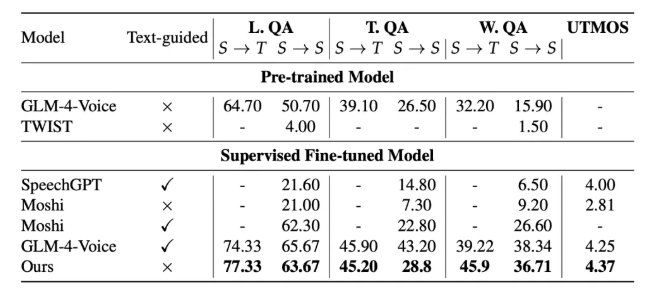
令人惊艳的性能表现
数据讲述了一个令人印象深刻的故事:
- 复杂语音任务中仅4.1%的词错误率——优于Meta的SpeechGPT和Google AudioLM
- 从语调识别情绪的准确率达到91.2%
- 中文语音质量获得接近人类水平的4.6 MOS评分(满分5分)
团队提供了两个版本:48kHz的专业录音棚品质版本和16kHz的轻量级版本,后者可在单块RTX4090 GPU上流畅运行且延迟低于300ms——足以满足实时移动应用需求。
未来发展方向?
研究人员并未止步于此。他们计划在2026年初发布"MOSS-Speech-Ctrl"版本——用户可以通过"听起来更兴奋"或"说慢一点"等语音指令进行控制。该技术已通过GitHub提供商业授权,并附带了创建自定义音色的工具包。
关键要点:
- 中国首个实现直接语音到语音对话的AI系统
- 通过保留常在文本转换中丢失的情感细微差别实现更高准确率
- 轻量级版本支持消费级硬件的实时使用
- 即将推出的控制功能将允许对话中实时调整发声风格