字节跳动发布OmniHuman-1.5:AI生成视频技术重大突破
字节跳动发布OmniHuman-1.5:AI视频生成技术飞跃
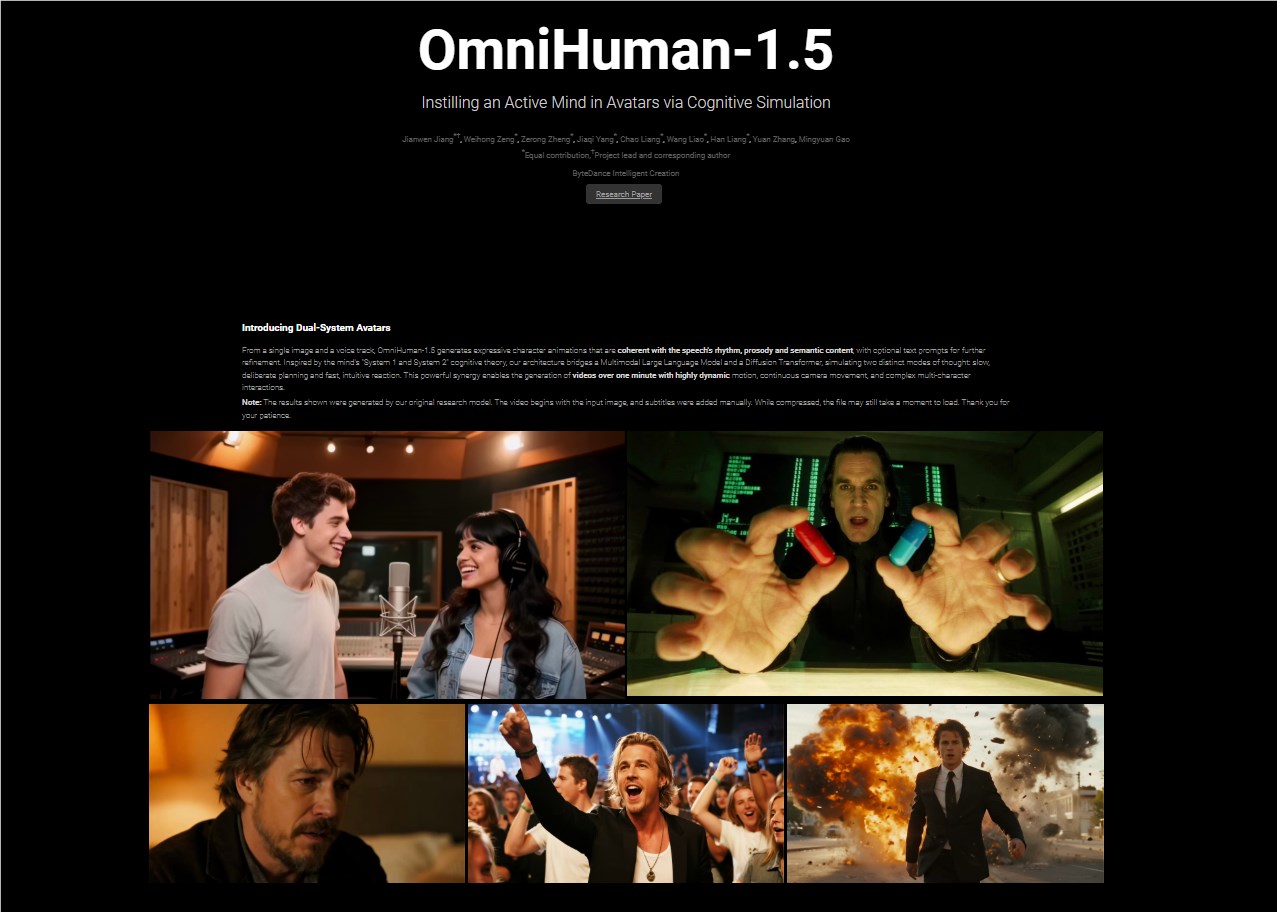
字节跳动数字人团队推出OmniHuman-1.5,这是其AI驱动视频生成技术的重大升级。这款多模态解决方案仅需单张图像和音频输入即可生成高度逼真的视频,标志着数字人应用的新里程碑。
项目地址: https://omnihuman-lab.github.io/v1_5/
技术进展
OmniHuman-1.5在核心技术基础上实现了真实感与泛化能力的提升。字节跳动团队优化的训练策略使动作、唇形同步和情感表达更加自然。无论是真实人物还是动画角色,系统都能生成与音频内容完美契合的高质量画面。
突破性功能
双人音频驱动是AI视频生成领域的首创功能,可捕捉多个角色间的互动效果,特别适合表演场景。此外,OmniHuman-1.5支持超过一分钟的长视频生成,同时保持连续性和身份一致性——这对演讲或音乐视频至关重要。
增强创意性
除机械动作外,系统能感知音频情绪并相应调整面部表情和肢体语言。新增的文本提示功能允许用户自定义场景或动作,提供更大创作灵活性。
多样化应用
OmniHuman-1.5对真实与非真实角色(如动漫或3D形象)均有出色表现,适用于游戏、VR和AR领域:
- 影视制作: 快速生成虚拟演员动画
- 虚拟主播: 动态实时互动
- 教育领域: 制作生动教学视频
- 营销推广: 打造品牌虚拟代言人
现存挑战
尽管取得进展,仍存在以下问题:
- 随机的音频-动作关联可能导致不自然运动
- 高计算需求可能限制普及度
字节跳动团队计划通过精细化动作控制和模型压缩来解决这些问题。
核心亮点
- 真实感升级: 更自然的动作与口型同步
- 双人场景: 业界首创多角色支持
- 情感AI: 根据音频语调调整表情
- 跨行业应用: 覆盖影视、教育到广告领域