蚂蚁集团dInfer将扩散模型速度提升10倍
蚂蚁集团发布突破性dInfer框架
蚂蚁集团正式推出dInfer——业界首个专为扩散语言模型设计的高性能推理框架。这一开源创新实现了前所未有的速度(比NVIDIA Fast-dLLM快10.7倍),同时保持可比性能指标。
基准测试表现
标准化测试中:
- 在HumanEval代码生成任务中达到1011 tokens/秒(单次推理)
- 平均速度为681 tokens/秒,对比Fast-dLLM的63.6 tokens/秒(8块H800 GPU)
- 在vLLM框架上运行时,比自回归模型Qwen2.5-3B快2.5倍
技术突破
扩散语言模型将文本生成视为去噪过程,具有以下优势:
- 高并行能力
- 全局上下文感知
- 灵活的结构设计
但先前实现存在关键局限:
- 过高的计算成本
- KV缓存效率低下
- 并行解码挑战
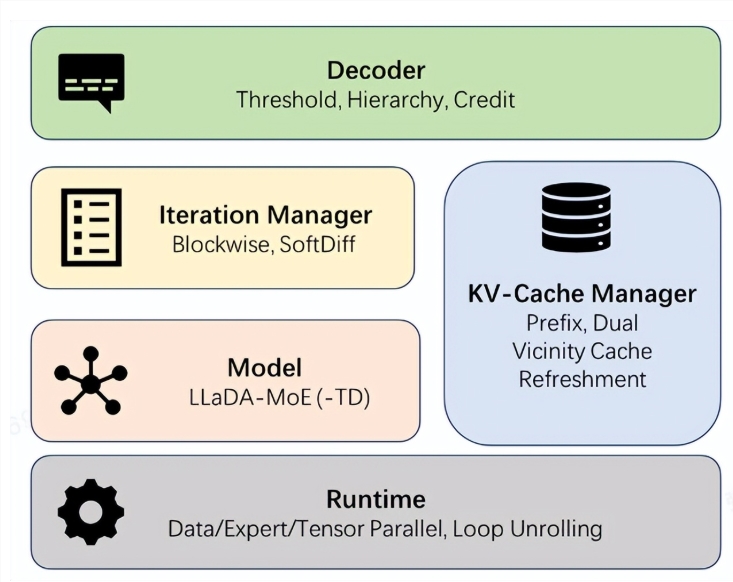
dInfer通过四大模块化组件解决这些问题:
- 模型接入层
- KV缓存管理器
- 扩散迭代控制器
- 自适应解码策略
类似乐高的架构允许开发者独立优化每个组件,同时保持标准化评估协议。
行业影响
该框架连接前沿研究与实际部署场景:
- 实现受速度限制的实时应用
- 为AGI发展路径开辟新可能
- 相比自回归方法提供可量化的性能优势
"这次发布不仅仅是速度的提升,"蚂蚁集团发言人表示,"更是要创建一个生态系统,让扩散模型能与传统架构共同发挥全部潜力。"
公司邀请全球研究者通过其开源平台协作优化该框架。
关键要点:
- 10倍速度提升超越现有解决方案
- 首个超越自回归基准的扩散模型
- 模块化设计支持针对性优化
- AGI发展时间线的潜在变革者

