Ant Group's BaiLing Team Open Sources Efficient AI Model
Ant Group's BaiLing Team Releases Revolutionary AI Model
Amid fierce competition in AI development, Ant Group's BaiLing large model team has open-sourced Ring-flash-linear-2.0-128K, a groundbreaking model designed specifically for ultra-long text programming applications. This release marks a significant advancement in efficient AI inference and long-context processing.
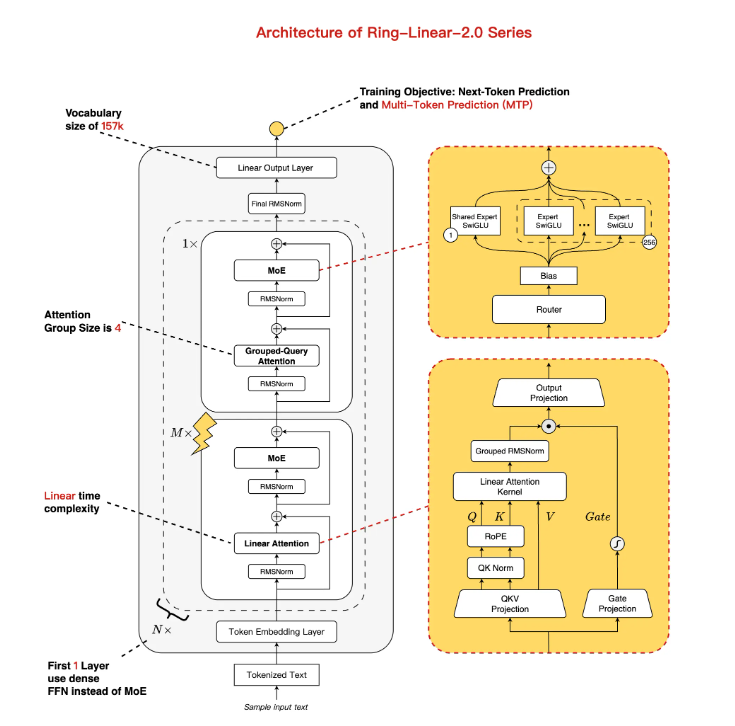
Hybrid Architecture Delivers Unprecedented Efficiency
The model features an innovative hybrid linear + standard attention mechanism combined with a sparse MoE (Mixture of Experts) architecture. With total parameters scaled at 104B but only 6.1B activated during operation (4.8B excluding embeddings), the system achieves:
- Near-linear time complexity
- Constant space complexity
- Generation speeds exceeding 200 tokens/second at 128K context on H20 hardware
- Three times faster daily use speeds compared to traditional models
The architecture is particularly optimized for resource-limited scenarios while maintaining performance comparable to 40B dense models.
Enhanced Training Yields Superior Reasoning Capabilities
Building upon the Ling-flash-base-2.0 foundation, the model underwent:
- Additional training on 1T tokens of high-quality data
- Stable supervised fine-tuning (SFT)
- Multi-stage reinforcement learning (RL)
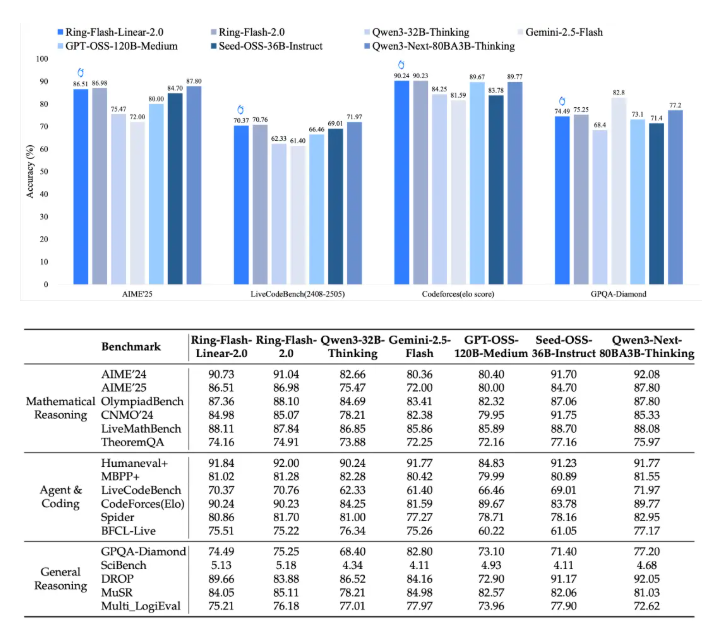
The training process overcame traditional instability issues in MoE long-chain reasoning through Ant's proprietary "Icepop" algorithm. Benchmark results demonstrate exceptional capabilities:
- 86.98 score in AIME2025 math competition
- 90.23 Elo rating in CodeForces programming tests
- Outperforms 40B dense models like Qwen3-32B in logical reasoning and creative writing tasks
Long Context Handling Redefines Programming Efficiency
The model natively supports 128K context windows, expandable to 512K using YaRN extrapolation technology. Performance highlights include:
- Prefill phase throughput nearly 5× higher than Qwen3-32B
- Decoding phase achieving 10× acceleration
Maintains high accuracy even in 32K+ context programming tasks without "model leakage" issues The system proves particularly effective for:
- Front-end development
- Structured code generation
Agent simulation scenarios
Open Source Availability Accelerates Adoption
The BaiLing team has made the model available on:
/div>">Hugging Face ">ModelScope ">">">">">">">">">">">Support includes BF16/FP8 formats and easy integration with popular frameworks like Transformers, SGLang, and vLLM."";"""Technical documentation is available on arXiv (https://arxiv.org/abs/2510.19338).""",,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,""",,,,"",,"",,"",,"",,"",,"",,"",,"",,"",,"".'''''''''''''''',,,,,,,,,,,,''''',,,,,,,,''''',,,,,,,,''''',,,,,,,,''''',,,,,,,,''''',,,,,,,,''''',,,,,,,,''''',,,,,,,,''''',,,,,,,,''''',,,,,,,,''''',,,,,,,,''''',,,,,,,,''''','', '''Key Points:'''''- Combines hybrid linear attention with MoE architecture'- Achieves SOTA performance with only 6.1B activated parameters'- Native 128K context support expandable to 512K'- Sevenfold efficiency improvement over previous versions'- Available now on Hugging Face and ModelScope