蚂蚁集团与中国人民大学联合发布首个原生MoE架构扩散语言模型
蚂蚁集团与中国人民大学发布突破性LLaDA-MoE模型
在2025外滩大会上,蚂蚁集团与中国人民大学联合推出LLaDA-MoE——业界首个原生混合专家(MoE)架构扩散语言模型(dLLM)。这一突破性成果挑战了语言模型必须采用自回归架构的传统认知。
核心创新
LLaDA-MoE模型基于约20TB数据从头训练,在工业级规模训练中展现出卓越的可扩展性和稳定性。其性能超越此前稠密架构的扩散语言模型如LLaDA1.0/1.5和Dream-7B,并与同等规模的自回归模型如Qwen2.5-3B-Instruct持平。值得注意的是,该模型仅激活总参数量70亿中的14亿参数即实现这一成就。

配图:中国人民大学与蚂蚁集团联合发布首个MoE架构扩散模型LLaDA-MoE
性能亮点
在蚂蚁统一评估框架下,LLaDA-MoE在包含HumanEval、MBPP和GSM8K在内的17个基准测试中平均提升达8.4%。其领先LLaDA-1.5达13.2%,并与Qwen2.5-3B-Instruct表现相当,验证了MoE架构在dLLM领域的"放大器效应"。
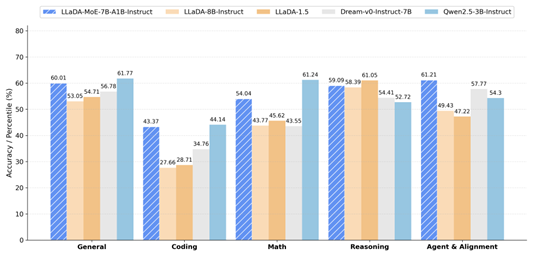
配图:LLaDA-MoE与其他模型的性能指标对比
技术突破
蚂蚁集团通用人工智能研究中心主任兰震中强调,该模型标志着dLLM向更大规模扩展迈出重要一步。团队基于LLaDA-1.0重写训练代码,并采用蚂蚁分布式框架ATorch实现并行加速。
中国人民大学助理教授*李崇轩指出,传统自回归模型难以处理双向token依赖关系,而LLaDA-MoE的并行解码机制有效解决了这一局限。
开源承诺
蚂蚁集团计划开源包括模型权重在内的全套资源,同时提供专为dLLM并行优化的定制推理引擎——据称其性能超越NVIDIA的fast-dLLM解决方案。技术报告与代码将在 GitHub*和 Hugging Face*平台发布。
关键要点:
- 首个原生MoE架构扩散语言模型(dLLM)
- 基于20T数据训练,总参数量70亿(激活14亿)
- 超越稠密扩散模型;媲美自回归同类产品
- 即将开源模型权重及推理框架