阿里巴巴发布FunAudio-ASR语音识别系统,突破性降噪技术引领行业
阿里巴巴FunAudio-ASR重新定义语音识别标准
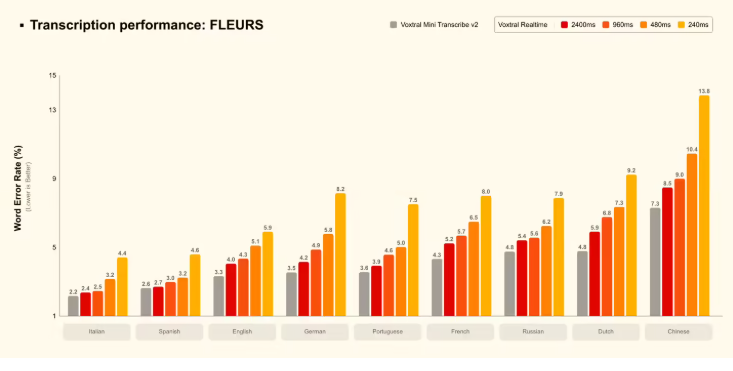
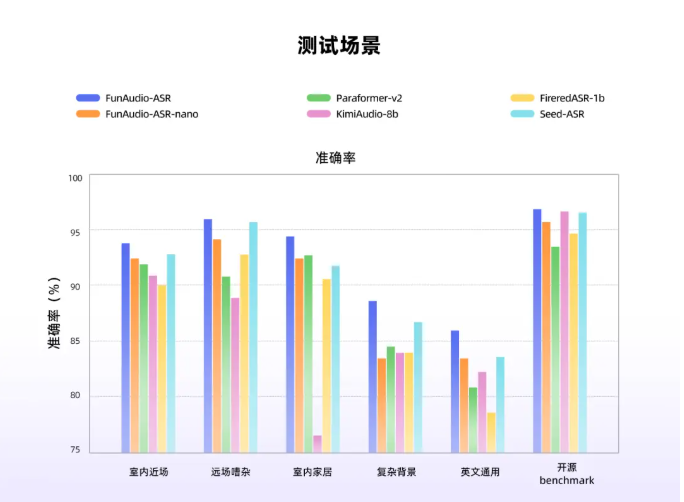
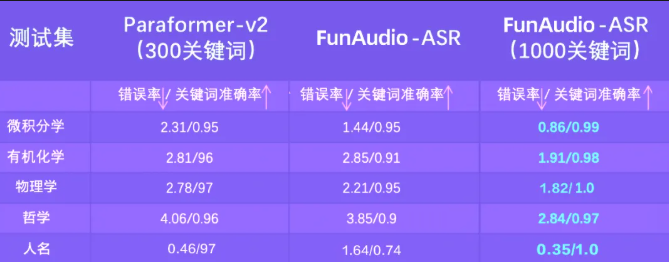
阿里巴巴集团通义实验室推出的FunAudio-ASR是一款端到端语音识别模型,通过创新的上下文模块显著提升了嘈杂环境下的识别准确率。这项技术进步将幻听率从78.5%降至仅10.7%,实现近70%的改善,为行业设立了新基准。
技术突破
该模型基于数千万小时的音频数据训练而成,并整合了大语言模型的语义理解能力。测试显示在以下挑战性场景中表现优于Seed-ASR和KimiAudio-8B等竞品:
- 远场音频采集
- 高噪声环境
- 多人讲话场景
该系统在会议、公共场所等传统上受背景噪音影响识别质量的商业应用中表现尤为突出。
部署选项
为满足不同用户需求,阿里巴巴提供:
- 完整版:为企业应用提供最高精度
- FunAudio-ASR-nano轻量版:在降低计算需求的同时保留核心功能
轻量版变体可在各种硬件配置上实现经济高效的部署,而不会造成显著的性能损失。
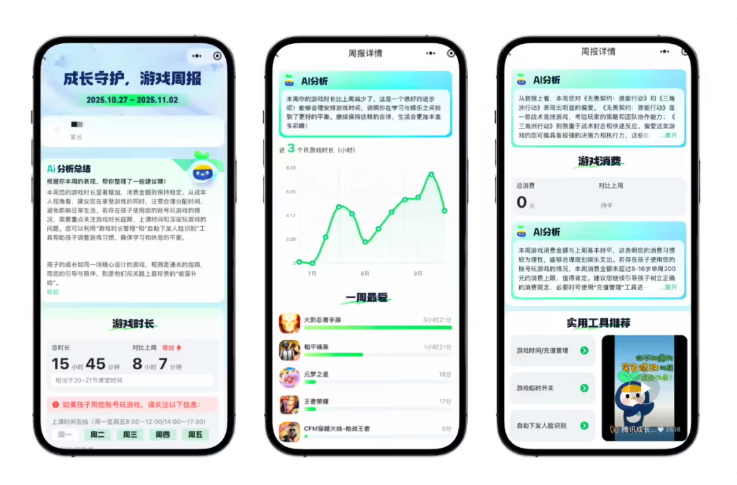
当前应用案例
该技术已赋能多个实际应用场景:
- 钉钉"AI笔记"功能
- 视频会议系统
- 钉钉A1硬件设备 开发者可通过阿里云百炼平台访问API,轻松集成至现有系统。
行业影响
此次发布标志着以下领域的重大进步:
- 商务通讯工具
- 无障碍技术
- AI转录服务 通过显著提升嘈杂环境下的可靠性,FunAudio-ASR消除了语音识别广泛普及的主要障碍。
关键亮点:
- 幻听率降低70%,相较前代解决方案 上下文模块实现前所未有的准确度提升 双版本部署满足不同资源需求 已在阿里巴巴商务通讯生态中全面应用 API开放加速第三方采用