阿里巴巴AI编程助手逼近全球排名榜首
阿里巴巴编程AI取得新突破
强势夺得亚军
中国的通义千问3.7-Max在编程界掀起波澜,斩获Code Arena权威排行榜亚军。以1541分的成绩,它仅次于Claude最新模型,同时超越了GPT-5.5和Gemini3.5Flash等重量级选手。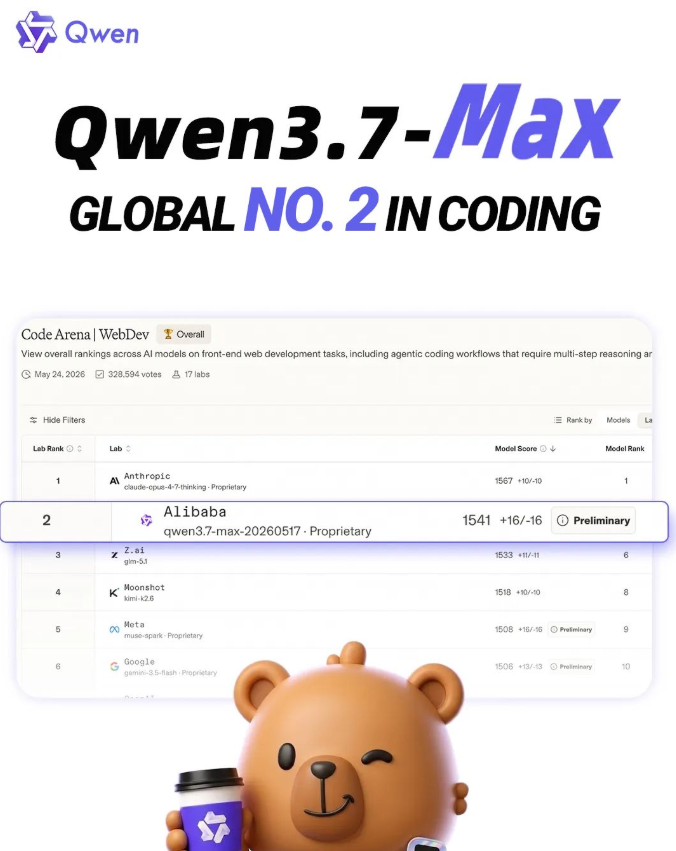
这一成就为何引人注目?该模型不仅能解决编码难题——更能在实际开发环境中游刃有余。从调试复杂系统到管理多文件项目,通义千问3.7-Max展现了可应用于真实工作场景的实用技能。
为持久战而生
该模型的突出特点?耐力。当大多数AI助手在短暂爆发后效率下降时,通义千问3.7-Max能够:
- 保持专注长达35小时不间断
- 执行超过1,000次工具调用而不会疲软
- 将两周项目压缩至单日完成
这种持久力彻底改变了开发者的工作方式。想象一个不下班的AI伙伴——能够通宵重构代码或进行马拉松式调试,同时保持稳定表现。
不止于编码
除了原始编程能力,通义千问3.7-Max在实际应用中同样出色:
- 框架灵活性:与现有工具(包括Claude生态系统)无缝协作
- 成本效益:提供顶级性能而不需顶级价格
- 错误修正:在长时间会话中从错误中学习
"这不仅是升级——它正在改变我们对AI协作的认知,"一位行业分析师指出。该模型处理长期、多步骤项目的能力表明,AI正从有用助手进化为可靠队友。
未来展望
随着通义千问3.7-Max的广泛应用,开发者预期项目周期将缩短,深夜编码的日子会减少。它的成功也标志着中国在AI开发工具领域日益增长的影响力,为全球用户提供了西方开发模型之外的新选择。
关键点:
- 在Code Arena全球编程基准测试中荣获亚军
- 35小时连续运行为AI耐力设立新标准
- 适用于各种复杂开发场景的真实世界应用性
- 相较于成熟AI编码工具的高性价比替代方案