阿里巴巴开源先进AI模型Qwen3-Next-80B-A3B
阿里巴巴发布尖端AI模型Qwen3-Next-80B-A3B
阿里巴巴通过开源其Qwen3-Next-80B-A3B模型在人工智能领域引起轰动,这标志着AI生成内容(AIGC)技术的一个重要里程碑。此次发布彰显了阿里巴巴推动AI研究并将最先进工具提供给全球开发者的承诺。
突破性性能指标
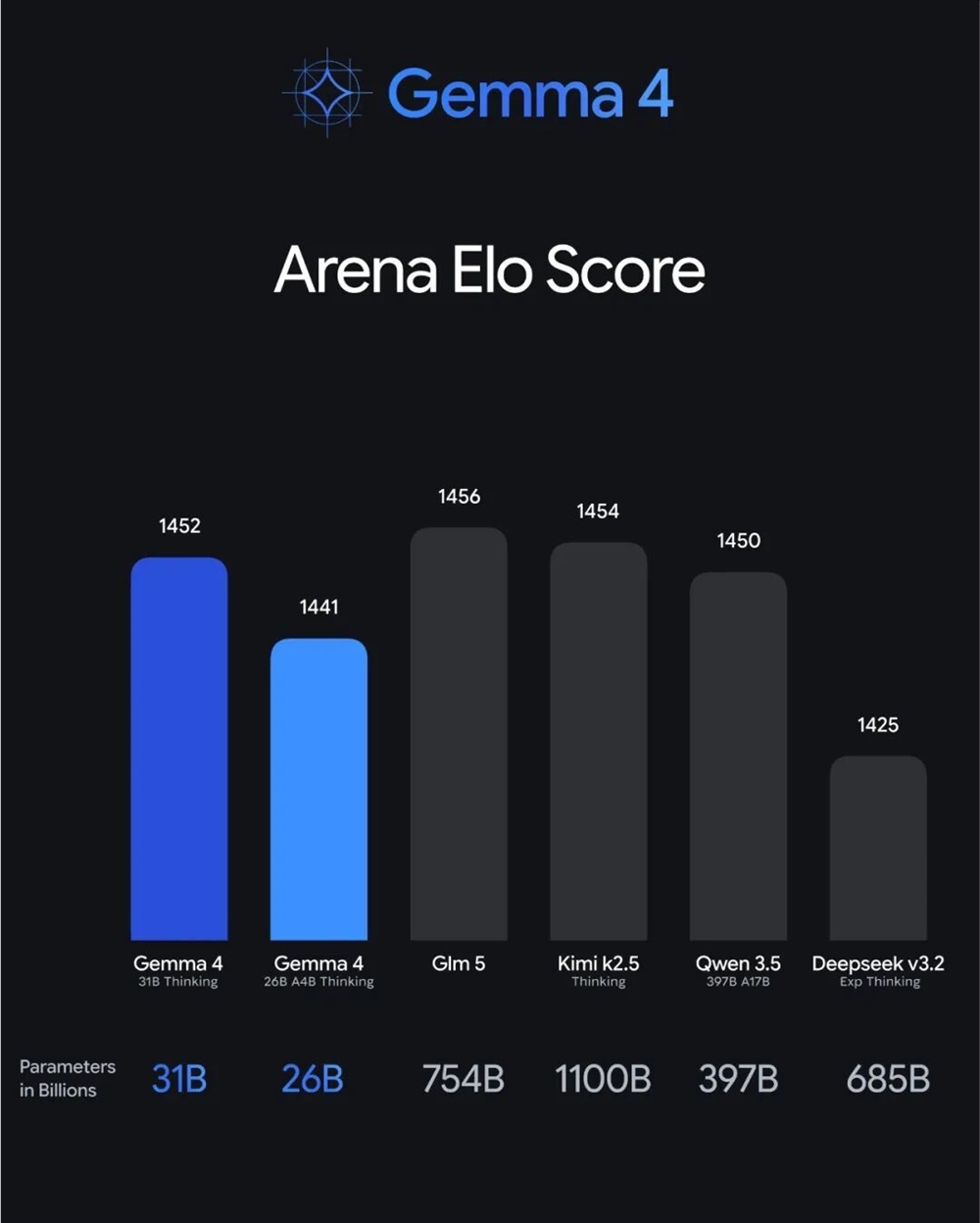
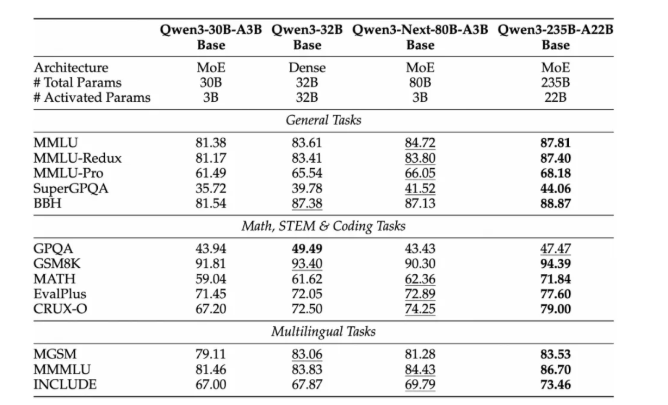
新模型拥有800亿总参数,但在推理时仅激活30亿参数,与上一代Qwen3-32B相比,训练成本降低了90%。更令人印象深刻的是,它在处理超过32K tokens的超长文本时,实现了10倍的推理效率提升。
在基准测试中,Qwen3-Next在指令执行和长上下文任务上匹配甚至超越了阿里巴巴旗舰级Qwen3-235B模型。它还优于谷歌最新的Gemini-2.5-Flash推理模型。
创新架构设计
其核心创新在于结合了以下两种机制的混合专家架构:
- Gate DeltaNet机制
- Gate注意力系统
这种新颖的方法解决了传统注意力机制在处理长上下文时的局限性,同时保持了处理速度。在训练过程中,该模型采用了高稀疏性专家混合(MoE)结构,在不影响性能的情况下优化了资源利用率。
增强的处理能力
关键技术进展包括:
- 多token预测机制:提升了推测解码性能
- 优化预训练:仅用之前9.3%的训练成本就取得了更好的结果
- 卓越的吞吐量:对长文本的处理能力提升了7倍,并在扩展上下文中保持了10倍的速度优势
该模型在技术能力和实际应用潜力上均实现了重大飞跃。
行业影响与可用性
此次发布在开发者和研究人员中引发了极大的兴奋:
- 在线演示地址:chat.qwen.ai
- 开源仓库:Hugging Face 通过此类突破性发布,阿里巴巴继续巩固其作为AI创新领导者的地位。 ### 关键点: 🌟 800亿参数模型,推理时仅激活30亿参数 🔍 混合专家架构实现卓越的上下文处理能力 🚀 在长文本场景下提供7-10倍的吞吐量提升 💰 实现90%的训练成本降低 🏆 超越谷歌的Gemini-2.5-Flash