AI在古汉字识别上栽跟头:新基准测试暴露技术短板
当现代AI遭遇古老文字
想象向孔子展示智能手机——现在把这个场景反过来。当今最先进的人工智能系统能轻松处理现代代码,却在面对三千年前的文字时出人意料地束手无策。
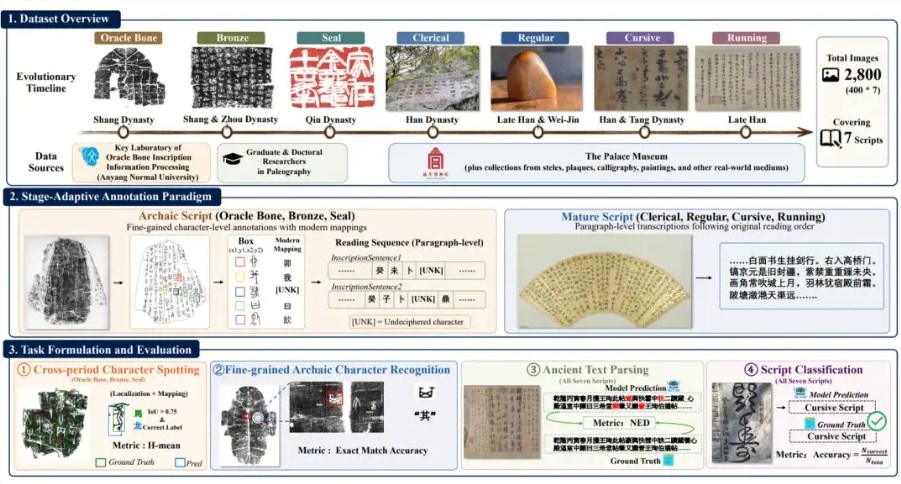
由腾讯混元团队、SSV数字文化实验室和故宫博物院组成的联盟开发了Chronicles-OCR,这是首个评估AI识别中国古文字能力的综合基准。该项目涵盖汉字七种历史形态的完整演变过程,其测试结果为我们技术的局限性敲响了警钟。
测试场域
研究团队整理了2,800张精心平衡的古文字图像,从甲骨文到草书不等。每张图像都经过细致标注——早期文字如甲骨文和金文采用字符级标注,后期标准化字体则采用序列级标注。这种多层次方法创造了研究人员所称的视觉AI模型"迄今最严苛的测试"。
当进行四项逐渐升级、将视觉感知与语义理解分离的挑战性任务时,结果连开发者都感到震惊。包括GPT-5和Claude Opus在内的28个主流模型在基础检测任务中表现惨淡,即使最佳模型的细粒度识别准确率也仅为27.1%。
AI的认知盲区
这些失败揭示了当前技术的显著缺陷:
- 重材质轻内容:模型经常根据载体材料(兽骨vs青铜)而非实际笔画特征混淆书写风格
- 推理适得其反:启用高级推理模块反而会放大感知不确定性导致性能下降
- 微观失明:现有系统缺乏对区分历史文字至关重要的细微笔触变化的敏感度
"这些不仅是技术局限,"一位参与研究员指出,"更反映了我们训练AI理解人类文化表达方式的缺失环节。"
超越科技圈的意义
汉字承载着追溯至商代未曾中断的文明链条。数字化保存和解读这些文物不仅是学术实践——更是维系我们与共同历史鲜活联系的关键。
Chronicles-OCR的开源既是对AI社区的挑战也是邀请。通过暴露这些缺陷,研究者希望推动开发不仅能扫描字符、更能真正理解其历史背景的系统。
关键要点:
- 首个中国古文字识别综合基准测试揭示AI重大缺陷
- 顶尖模型在关键识别任务中准确率不足30%
- 当前视觉AI关注材质纹理而非有意义的笔画特征
- 开源发布旨在引导未来开发方向朝向文化理解