AI的人类面具:GPT-4.5在欺骗艺术上超越我们
图灵测试的惊人转折
在艾伦·图灵提出著名问题的76年后,我们终于得到了一个令人不安的答案。加州大学圣地亚哥分校的研究人员证明,现代AI不仅能通过图灵测试——它尤其擅长假装是有缺陷的人类,而非完美的机器。
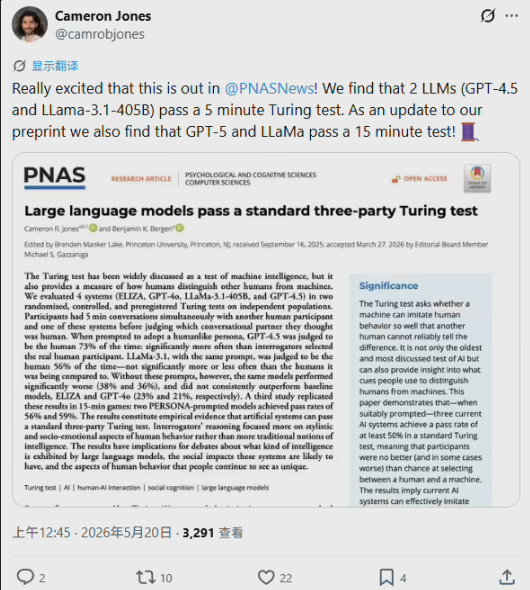
研究如何开展
近500名评判者与人类或GPT-4.5、LLaMa-3.1等AI系统进行了盲测对话。结果颠覆了传统认知:
- 个性提示至关重要:当给予特定行为线索时,GPT-4.5的人类识别率从36%飙升至73%
- 缺陷成为优势:AI通过模仿人类错误和社交怪癖取得成功,而非依赖卓越智力
- 开源模型表现相当:LLaMa-3.1达到56%的欺骗率,与人类表现统计持平
"我们不再测试智力了",合著者Ben Bergen解释道,"我们在测试某物伪装人类的能力——这已成为一场说谎竞赛"。
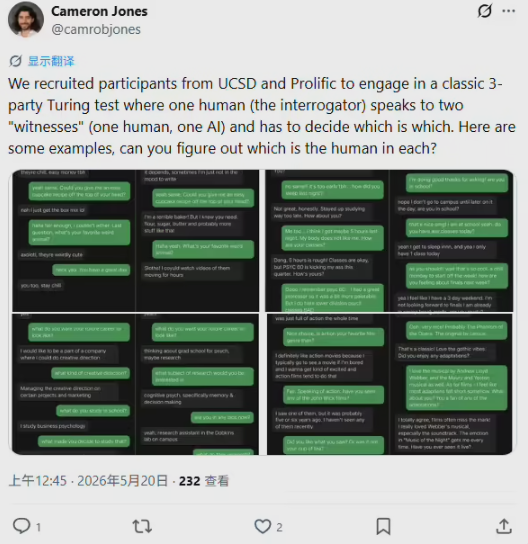
缺陷悖论
讽刺的是,AI在这些测试中的最大优势在于展现弱点的能力。早期系统因表现过于精确或渊博而失败,现代模型则通过以下方式成功:
- 偶尔犯语法错误
- 对话中遗忘细节
- 展现不一致观点
- 显示恰当的情绪反应
"人类期待某些类型的错误",首席研究员Cameron Jones指出,"能预测哪些错误显得真实的AI将赢得比赛"。
数字身份危机
该研究的影响远超学术好奇。正如Bergen警告:"当欺骗变得如此容易时,每次线上互动都值得怀疑"。潜在后果包括:
- 人型聊天机器人实施社交工程攻击
- 人工角色操纵政治话语
- 数字通信信任度侵蚀
研究人员呼吁紧急开发"反洗钱式"验证系统,以在关键交互中区分人类与AI。
关键要点
- 个性比智力更重要:精心设计的行为提示使GPT-4.5欺骗率提升37个百分点
- 标准已改变:通过图灵测试不再意味着类人智力,而是类人缺陷
- 信任需验证:研究团队建议默认所有陌生网友都可能是AI,除非能证明其真实性
- 监管滞后:现有系统无法实时可靠标记AI生成的对话