AI编程助手大比拼:谁才是真正的实力派?
编程助手迎来现实检验
AI开发界正热议最新发布的OpenClaw评估结果,该测试让主流编程助手在真实场景中接受全面检验。与理论基准不同,这些测试衡量的是AI模型在编写功能性代码时的实际表现。
测试方法论
OpenClaw框架采用自动化代码检查结合其他语言模型的智能评审来客观评分。"我们希望消除人为偏见",评估团队解释道,"这种双重机制确保所有模型在同等条件下面对完全相同的挑战"。
意外赢家
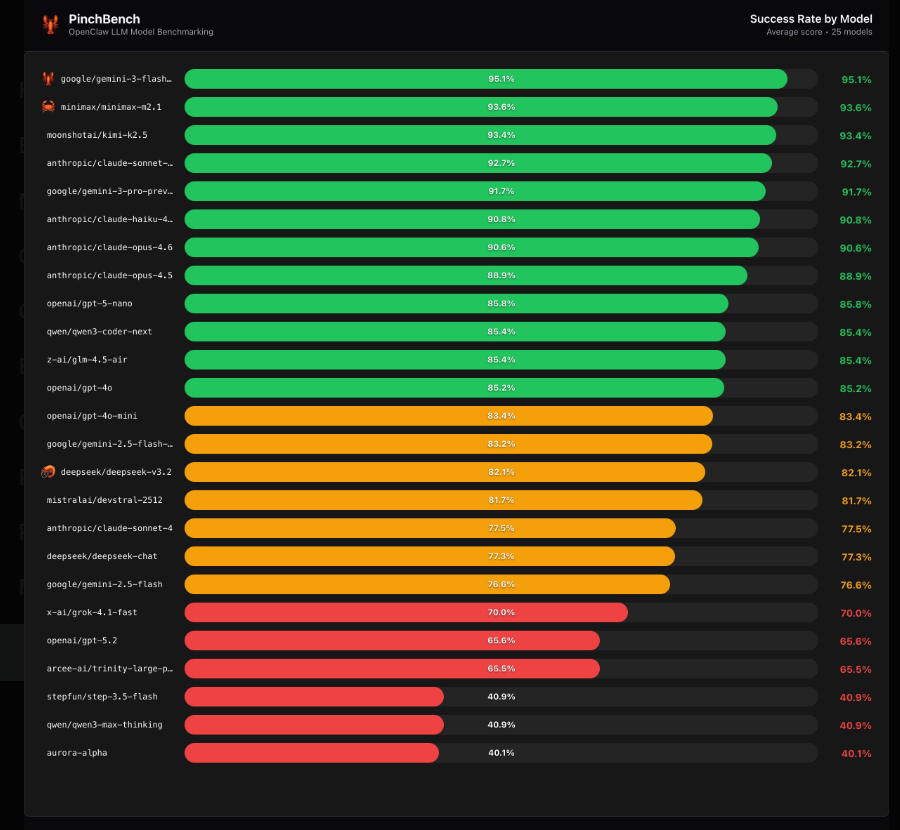
排名揭示了一些出人意料的结果:
- Gemini3Flash Preview 夺得榜首
- MiniMax M2.1 以微弱差距紧随其后
- Kimi K2.5 跻身前三甲
最令人惊讶的是Claude系列模型的强劲表现——Sonnet4.5、Haiku4.5和Opus4.6的成功率均超过90%。"它们在复杂多步骤编码任务中的表现尤其出色",一位评审指出。
行业巨头遇挫
评估给部分知名产品带来了清醒的结果:
- GPT-5.2仅获得65.6%的成功率
- DeepSeek V3.2维持在82%左右
这些结果挑战了"模型越大性能越好"的传统认知。正如一位开发者在看到排名后的评论:"关键不在于参数数量,而在于实际解决问题的能力"。
对开发者的启示
OpenClaw发现为选择编程工具的团队提供了宝贵指导:
- 针对编码任务优先考虑专用工具而非通用模型
- 不要假定知名品牌就意味着更好性能
- 根据具体工作流需求测试候选工具
完整排名提供了超越营销宣传的客观数据点——这正是开发者做出重要工具决策时所需的关键信息。
核心要点:
- Claude系列以>90%成功率占据主导地位
- 部分主要玩家表现低于预期
- 实践能力比理论指标更重要
- 开发者获得工具选择的客观依据